Анализируем, отправленные емайл сообщения для кандидатов, в R
dashboard, дашборд, R, анализ, емайл, email, сообщения
Что происходит с сообщениями, отправленные кандидатам?
Если ответить коротко, то не известно, но для рекрутера эта информация так же важна как и для маркетолога. Каждый рекрутер ежедневно отправляет десятки сообщений кандидатам. Поэтому почта до сих пор остаётся надёжным и важным рабочим инструментом. Сообщения могут быть различного характера. Переписка по эл. почте важна не только для того что бы отправить вакансию, но для того что бы договориться и/или подтвердить собеседование. И даже не смотря на широкое распространение мессенджеров, электронная почта остаётся надёжным каналом для связи с кандидатами.
Маркетологи давно пользуются различного рода трекерами для отслеживания действий пользователей во время проведения массовых рассылок. Данные анализируются, обрабатываются и принимаются решения для дальнейших маркетинговых активностей. Для hr специалиста эти инструменты полезны и нам так же хочется знать сколько человек открыло сообщений, сколько человек кликнуло по ссылкам, сколько времени уделяют на прочтение сообщений, какими устройствами пользуются. Однако у трекеров есть два недостатка, которые меня останавливали пользоваться ими. Во-первых, маркетинговые инструменты заточены для массовых рассылок и большой базы получателей. Соответственно все тарифы и статистика ориентирована для масштабных акций, которые происходят раз в течении недели, месяца, полгода и т.п. Для рекрутера это не лучший вариант. Например, в своей работе массовую рассылку не применяю, только персонализированные сообщения. Каждый день отправляю сообщения от нескольких штук до нескольких десятков. Во-вторых, они платные и аналитика заранее уже настроена, её не возможно подстроить под собственные нужды. Да, мне не хочется платить за то, что можно сделать самому и так как мне хочется. На мой взгляд, некоторые трекеры дают не полную информацию о поведении пользователей.
Для того что бы получить доступ к данным о реакции кандидатов нам потребуется: зарегистрированный аккаунт в сервисе mailgun.com, язык программирования R и IDE для него - RStudio и немного терпения. Mailgun выбрал из-за того что с помощью него можно отправлять до 10 000 сообщений в месяц бесплатно. Кроме того у сервиса постое и понятное API. А язык R выбран из-за своей простоты и универсальности. С помощью него одного мы будем подключаться к сервису и получать данные, затем их обработаем, визуализируем и выведем данные в браузере на экран.
Описанный метод может быть полезен в первую очередь рекрутерам фрилансерам или небольшим агентствам, т.к. решение простое, эффективное и аналитику легко настроить. Однако не стоит думать, что скрипт, который мы напишем может быть реализован, только в RStudio. Многие BI системы поддерживают язык R поэтому не составит труда запустить код, например, в Power BI, Tableau или Cluvio.
Создадим информационную панель для анализа емайл сообщений
В данной статье не будет рассказано о том, как установить язык программирования R, RStudio, и как настроить сервис mailgun для вашей почты. В интернете много информации на этот счёт, в том числе на русском языке. Поэтому предполагается, что у вас уже всё установлено и настроено. Единственное хочу предупредить, что для для эл. почты Яндекса настроить smtp не получится. Яндекс не позволяет менять сервера, но в gmail это возможно.
Подключаться к данным mailgun будем через API самого сервиса поэтому нам понадобится секретный ключ для того что бы мы смогли скачать данные. Войдите в свой аккаунт по ссылке https://app.mailgun.com/app/account/security/api_keys и увидите следующую информацию.
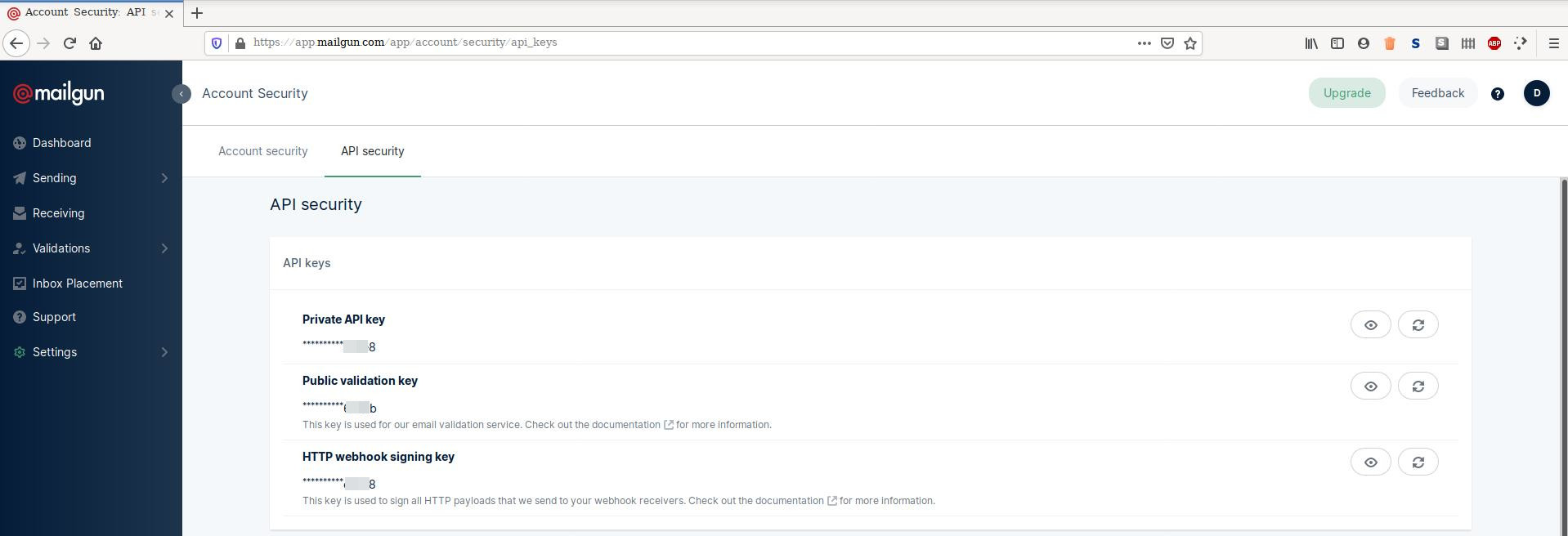
Вам нужно скопировать Private API key. Сохраните себе секретный ключ в отдельный файл, он нам скоро понадобится. Откроем IDE RStudio и установим необходимые пакеты в Console введите команду.
install.packages(c("httr", "tidyverse", "jsonlite", "plotly", "knitr", "flexdashboard"))Теперь создадим рабочий файл с расширением .Rmd в котором будет записан наш код. Итак, в RStudio в самом левом углу под главным меню нажимаем на белый квадрат с зелёным плюсом.
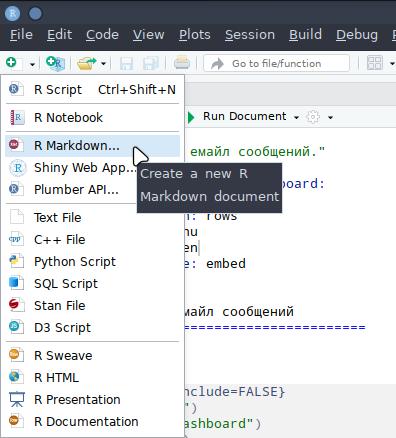
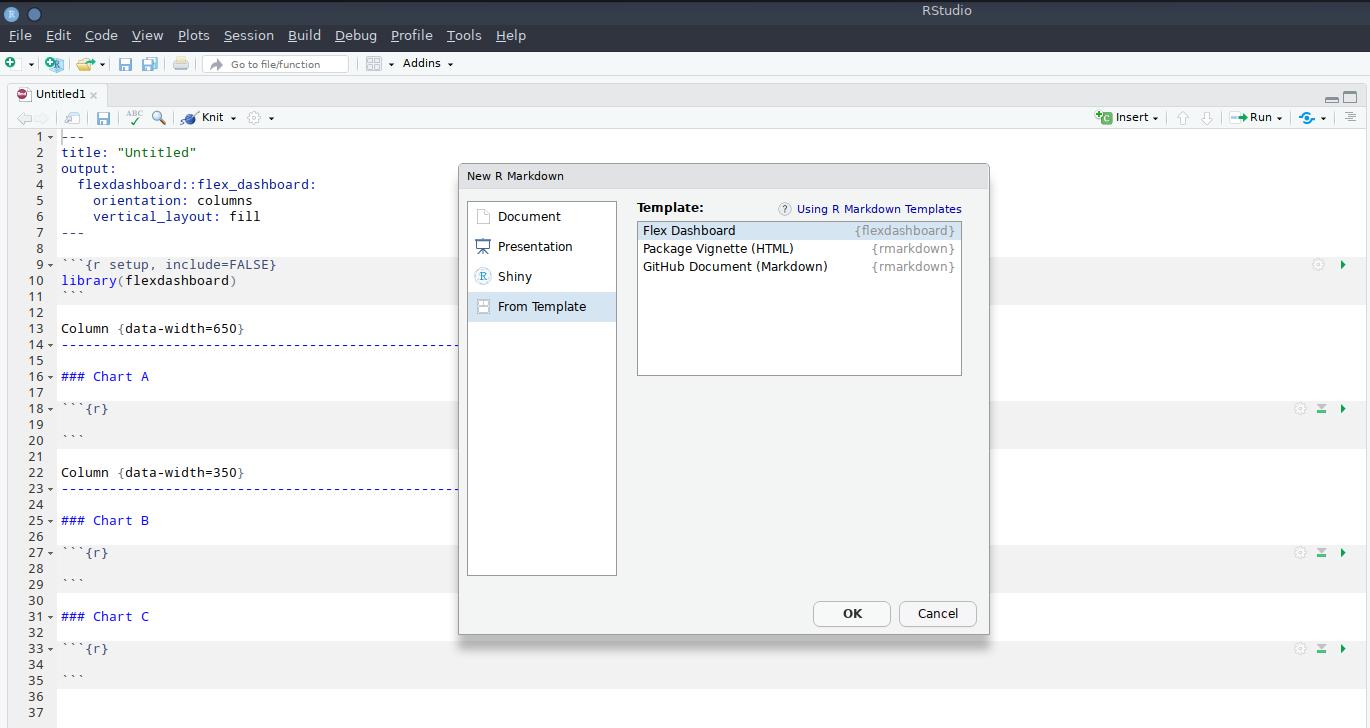
Выбираем R Markdown, затем в новом окне выбираем From Template и наконец Flex Dashboard. Выделите пункты как изображено на картинке и нажмите OK.
Предлагаю сразу создать специальную папку в домашней директории для хранения данных, а так же для созданного файла .Rmd. Например, директорию назовём mailgun, а рабочий файл dashboard.Rmd.
Самое время узнать какие данные нам может редоставить сервис mailgun. Следовательно мы можем сформулировать наши требования к информационной панели, т.е. какую информацию хотим видеть на экране монитора. Почтовый сервис даёт различную информацию, но для нас важны следующие данные:
- Дата и время
- Гео данные - страна, регион, город.
- IP адрес получателя.
- События и действия получателей с сообщениями.
- Данные о технологиях.
- Название или заголовок сообщений.
- Электронный адрес получателя.
- Время сессии в секундах.
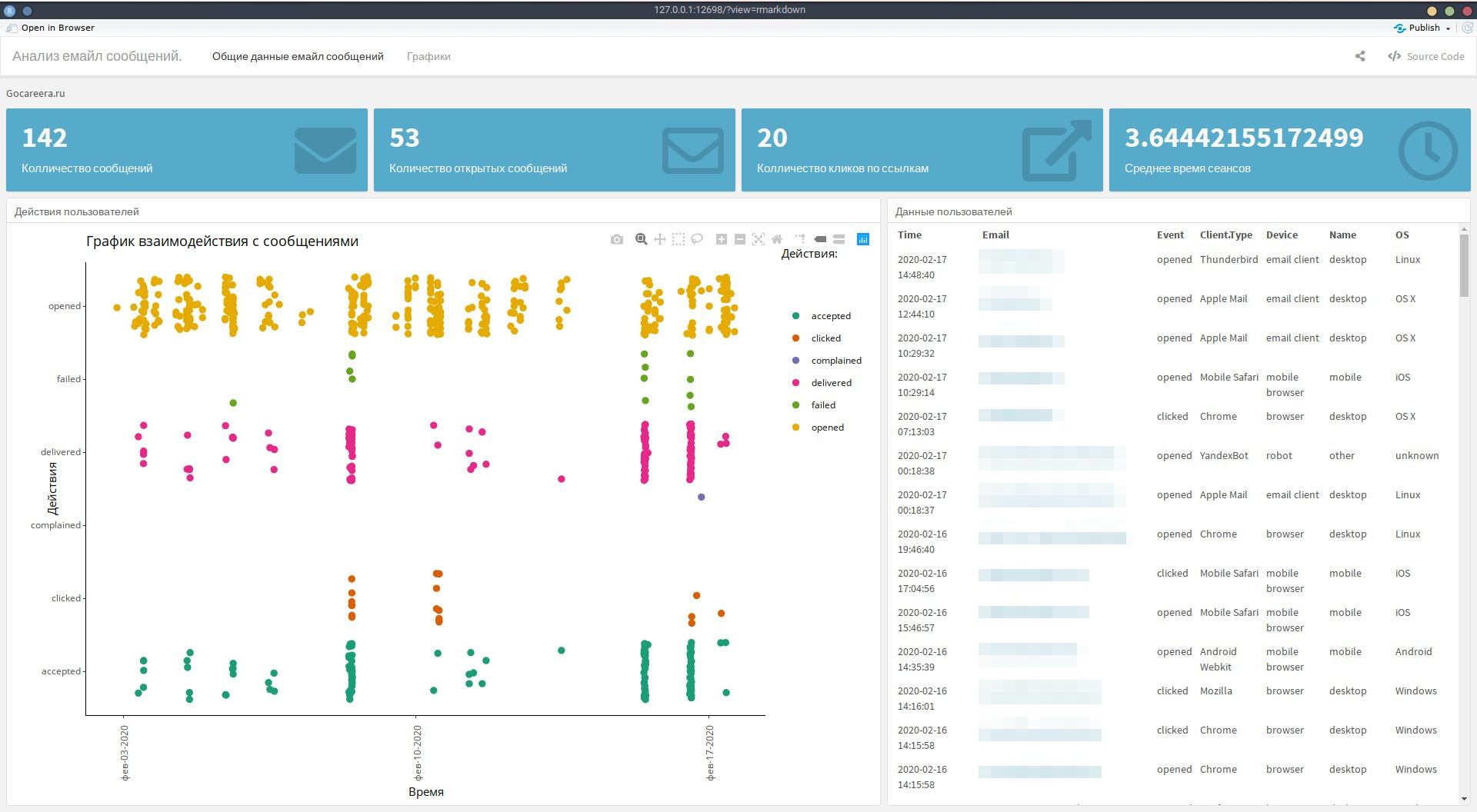
Исходя из этих данных решил, что в своём дашборде хочу видеть общее количество отправленных сообщений, количество открытых сообщений, количество кликов по ссылкам и среднее время сессий пользователей. Кроме этого графики количества всех событий по дням, технологий пользователей, времени сессий пользователей и график не доставленных сообщений. Кроме этого будут две таблицы. В первой будут данные о пользователях, которые открыли сообщения и кликнули по ссылкам. Во второй таблице будет информация о сообщениях, которые не были доставлены.
Приступим. Открываем рабочий файл dashboard.Rmd и отредактируем шапку файла. Вместо того что сгенерировано по умолчанию дополним немного более осмысленной информации. Заменим название заголовка будущего приложения и поменяем параметр orientation, параметр vertical_layout удалим, вместо него добавим параметр theme. В итоге у вас должно получиться следующее:
---
title: "Анализ емайл сообщений."
output:
flexdashboard::flex_dashboard:
author: Иван Иванов
orientation: rows
theme: lumen
runtime: shiny
---Для того что бы в будущем самостоятельно настраивать приложение и создавать собственные, рекомендую ознакомиться с документацией по ссылке https://rmarkdown.rstudio.com/flexdashboard/index.html. Кроме подробной документации о параметрах и дополнительных опциях вы можете посмотреть примеры работ.
Первым делом, что должно делать приложение это активировать нужные пакеты, подсоединяться через API к аккаунту, собрать данные и произвести первичную обработку.
library("knitr")
library("flexdashboard")
library("httr")
library("tidyverse")
library("jsonlite")
library("plotly")
data <- RETRY("GET", "https://Private_API_key@mailgun.net/v3/domain_name/events")
data <- stream_in(textConnection(gsub("\\n", "", data)))
data <- data.frame(data$items)Данные приходят в формате json, который необходимо предварительно обработать, а затем сохранить в стандартный data frame. Вспомните про ваш Private API key, здесь он понадобится, а так же название домена к которому будете подключаться. Следующим шагом нам нужно будет сохранить конкретные данные о времени, геолокации, технологиях пользователей в отдельные дата фреймы.
time <- as_tibble(data$timestamp)
geolocation <- as_tibble(data$geolocation)
ip <- as_tibble(data$ip)
event <- as_tibble(data$event)
os <- as_tibble(data$client.info)
message <- as_tibble(data$message$headers)
recipient <- as_tibble(data$recipient)
session <- as_tibble(data$delivery.status$`session-seconds`)Две небольшие, дополнительные манипуляции. Удалим столбец user-agent из дата фрейма os. А так же приведём формат даты и времени в удобный для нас вид Год-месяц-число Час-минута-секунда.
os$`user-agent` <- NULL
time <- as.POSIXlt(time$value, origin = "1970-01-01", tz = "UTC")Теперь данные нужно сохранить и более того в следующий раз мы должны будем новые данные дописывать к имеющимся, т.е. данные будут накапливаться регулярно. Для этого необходимо перейти в созданную директорию mailgun и записать туда дата фреймы.
setwd("~/mailgun") #(for linux)
write.table(time, "time.csv", append = TRUE, sep = ",")
write.table(geolocation, "geolocation.csv", append = TRUE, sep = ",")
write.table(ip, "ip.csv", append = TRUE, sep = ",")
write.table(event, "event.csv", append = TRUE, sep = ",")
write.table(os, "os.csv", append = TRUE, sep = ",")
write.table(message, "message.csv", append = TRUE, sep = ",")
write.table(recipient, "recipient.csv", append = TRUE, sep = ",")
write.table(session, "session.csv", append = TRUE, sep = ",")Очистим оперативную память программы. Это полезно делать по двум причинам. Во-первых, дальше будем работать только со свежими данными т.е. с данными которые мы очистили и обработали. Данные, которые сохраняются на диске ежедневно. Во-вторых, скриптовые языки не очень хорошо работают с оперативной памятью, они её постоянно забивают. Поэтому для скорости работы приложения лучше удалить лишнее и работать только с подготовленной информацией.
gc(reset=T)
rm(list=ls())Теперь загрузим в рабочую память программы данные, с которыми будем работать.
time <- read.csv("time.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Time"))
geolocation <- read.csv("geolocation.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Country", "Region", "City"))
ip <- read.csv("ip.csv", header = FALSE, row.names=NULL, col.names = c("V1", "IP"))
event <- read.csv("event.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Event"))
os <- read.csv("os.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Client Type", "Device", "Name", "OS"))
message <- read.csv("message.csv", header = FALSE, row.names=NULL, col.names = c("V1", "ID", "To", "From", "Subject"))
recipient <- read.csv("recipient.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Email"))
session <- read.csv("session.csv", header = FALSE, row.names=NULL, col.names = c("V1", "Session Time"))Объедим все данные в один дата фрейм, удалим столбцы V1, сохраним новый дата фрейм в формате tibble, а так же ещё раз очистим данные от дублей.
data <- cbind(time, geolocation, ip, event, os, message, recipient, session)
data <- as_tibble(data[, !(colnames(data) %in% "V1")])
data <- data[!duplicated(data), ]
data <- data[!(is.na(data$Time) | data$Time==""), ]Данные подготовлены и готовы для дальнейшей работы и визуализации. Из того, что я написал в требованиях к информационной панели предлагаю разбить информацию по двум экранам. Так будет проще анализировать информацию. В первой вкладке или на первом экране я размещу в самом верху данные в виде цифр о том сколько всего сообщений отправлено, сколько открыто сообщений, сколько кликов по ссылкам и среденее время сессий.
### Колличество сообщений
data2 <- data %>%
select(Email) %>%
distinct(Email, .keep_all = TRUE)
data2 <- lengths(data2)
renderValueBox({
valueBox(data2, icon = "fa-envelope")
})
### Количество открытых сообщений
data3 <- data %>%
select(Email, Event) %>%
filter(Event == "opened") %>%
distinct(Email, .keep_all = TRUE)
Event <- length(data3$Event)
renderValueBox({
valueBox(Event, icon = "fa-envelope-o")
})Колличество кликов по ссылкам
data4 <- data %>%
select(Event) %>%
filter(Event == "clicked")
data4 <- lengths(data4)
renderValueBox({
valueBox(data4, icon = "fa-external-link")
})Среднее время сеансов
data5 <- mean(data$Session.Time, na.rm = T)
renderValueBox({
valueBox(data5, icon = "fa-clock-o")
})Ниже разместим график действий пользователей с нашими сообщениями по датам.
### Действия пользователей {data-width=600}
p <- ggplot(data, aes(as.POSIXct(Time, "%Y-%m-%d %h:%m:%s"), Event, colour = Event, size = I(2))) +
geom_jitter() +
theme_classic() +
scale_color_brewer(palette = "Dark2") +
scale_x_datetime(date_labels = "%b-%d-%Y") +
theme(axis.text.x = element_text(angle=90, vjust=0.5), legend.position = "top") +
labs(title="График взаимодействия с сообщениями", x = "Время", y = "Действия", color='Действия:')
ggplotly(p)Графики будут интерактивными и в будущем мы сможет изучать их по дням или по конкретным действиям. Справа от графика разместим таблицу в которой будут указаны: эл. почта пользователя, действия пользователей, а так же информация об операционной системе, почтовом клиенте, браузере и девайсе. Снова удалим дубли и представим данные по убыванию по параметру времени.
### Данные пользователей {data-width=400}
data1 <- data %>%
filter(Event == "clicked" | Event == "opened") %>%
select(Time, Email, Event, Client.Type, Device, Name, OS) %>%
distinct(Email, Event, Client.Type, Device, Name, OS, .keep_all = TRUE)
data1 <- data1 %>%
arrange(desc(data1$Time), .by_group = TRUE)
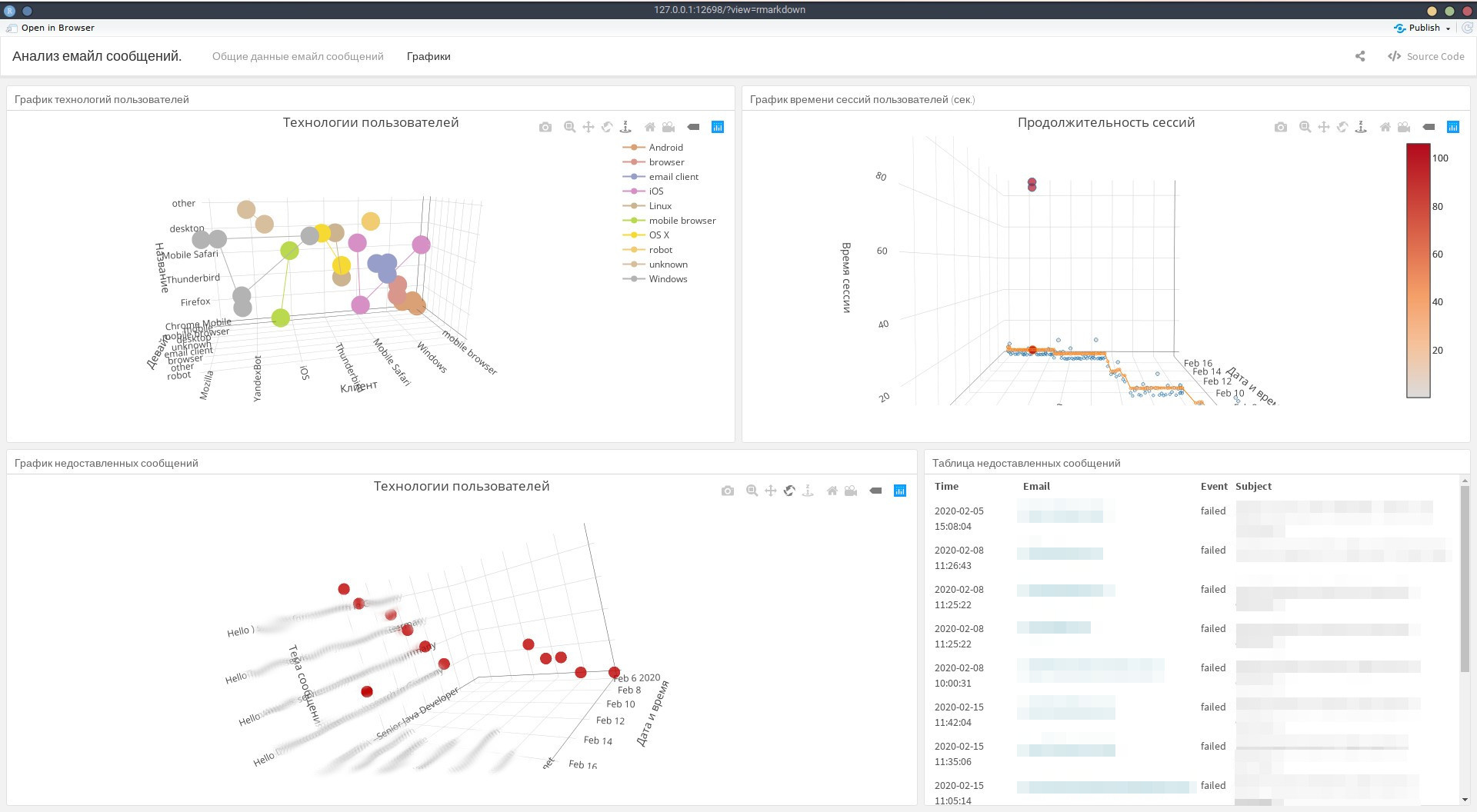
knitr::kable(data1[c("Time", "Email", "Event", "Client.Type", "Device", "Name", "OS")])Во второй вкладке или экране разместим три графика и одну таблицу. Для себя решил что 3d графики наиболее подходят для визуализации данных, которые мне необходимы. На первом графике предлагаю разместить информацию о технологиях, с помощью которых пользователи (кандидаты) читают сообщения.
### График технологий пользователей {data-width=800}
data6 <- data %>%
select(Client.Type, Device, Name, OS)
data6 <- data6[!(is.na(data6$Client.Type) | data6$Client.Type==""), ]
plot_ly(data = data6, x = ~Client.Type, y = ~Device, z = ~Name, color = ~OS, type = 'scatter3d', mode = "lines+markers") %>%
layout(title = 'Технологии пользователей',
scene = list(xaxis = list(title = 'Клиент'),
yaxis = list(title = 'Девайс'),
zaxis = list(title = 'Название')))Справа разместим второй график, который будет показывать время сессий пользователей, а так же визуализируем среднее значение.
### График времени сессий пользователей (сек.) {data-width=800}
data7 <- data %>%
select(Session.Time, Time, To)
data7 <- data7[!(is.na(data7$Session.Time) | data7$Session.Time==""), ]
plot_ly(data = data7, x = ~Time, y = ~To, z = ~Session.Time, size = ~Session.Time, type = 'scatter3d', mode = "markers",
marker = list(color = ~Session.Time, colorscale = c('#FFE1A1', '#683531'), showscale = TRUE)) %>%
add_trace(data=data7, z = mean(data7$Session.Time), type="scatter3d", mode="lines", showlegend = FALSE) %>%
layout(title = 'Продолжительность сессий',
scene = list(xaxis = list(title = 'Дата и время'),
yaxis = list(title = 'Емайл кандидата'),
zaxis = list(title = 'Время сессии')))Под графиком технологий пользователей разместим график не доставленных сообщений и уже справа от него таблицу с этими же данными.
### График не доставленных сообщений {data-width=1000}
data8 <- data %>%
filter(Event == "failed") %>%
select(Time, Event, Subject, Email)
plot_ly(data = data8, x = ~Time, y = ~Subject, z = ~Email, type = 'scatter3d', mode = "markers",
marker = list(size = 5,
color = 'rgba(152, 0, 0, .8)')) %>%
layout(title = 'Технологии пользователей',
scene = list(xaxis = list(title = 'Дата и время'),
yaxis = list(title = 'Тема сообщения'),
zaxis = list(title = 'Эл. адрес')))Таблица не доставленных сообщений
knitr::kable(data8[c("Time", "Email", "Event", "Subject")])На этом всё, информационная панель готова в итоге у вас может получиться примерно следующее.